mirror of
https://github.com/timerring/bilive.git
synced 2026-05-06 21:40:20 +08:00
feat: sensenova and unittest (#280)
* feat: sensenova and unittest * docs: update images
This commit is contained in:
17
README.md
17
README.md
@@ -17,6 +17,7 @@
|
||||
<img src="assets/zhipu-color.svg" alt="Zhipu GLM-4V-PLUS" width="60" height="60" />
|
||||
<img src="assets/gemini-brand-color.svg" alt="Google Gemini 1.5 Pro" width="60" height="60" />
|
||||
<img src="assets/qwen-color.svg" alt="Qwen-2.5-72B-Instruct" width="60" height="60" />
|
||||
<img src="assets/sensenova-brand-color.svg" alt="SenseNova V6 Pro" width="100" height="60" />
|
||||
</div>
|
||||
|
||||
<img src="assets/hunyuan-color.svg" alt="Tencent Hunyuan" width="50" height="60" />
|
||||
@@ -56,6 +57,7 @@
|
||||
- `GLM-4V-PLUS`
|
||||
- `Gemini-2.0-flash`
|
||||
- `Qwen-2.5-72B-Instruct`
|
||||
- `SenseNova V6 Pro`
|
||||
- **( :tada: NEW)持久化登录/下载/上传视频(支持多p投稿)**:[bilitool](https://github.com/timerring/bilitool) 已经开源,实现持久化登录,下载视频及弹幕(含多p)/上传视频(可分p投稿),查询投稿状态,查询详细信息等功能,一键pip安装,可以使用命令行 cli 操作,也可以作为api调用。
|
||||
- **( :tada: NEW)自动多平台循环直播推流**:该工具已经开源 [looplive](https://github.com/timerring/looplive) 是一个 7 x 24 小时全自动**循环多平台同时推流**直播工具。
|
||||
- **( :tada: NEW)自动生成风格变换的视频封面**:采用图生图多模态模型,自动获取视频截图并上传风格变换后的视频封面。
|
||||
@@ -71,7 +73,7 @@
|
||||
|
||||
项目架构流程如下:
|
||||
|
||||
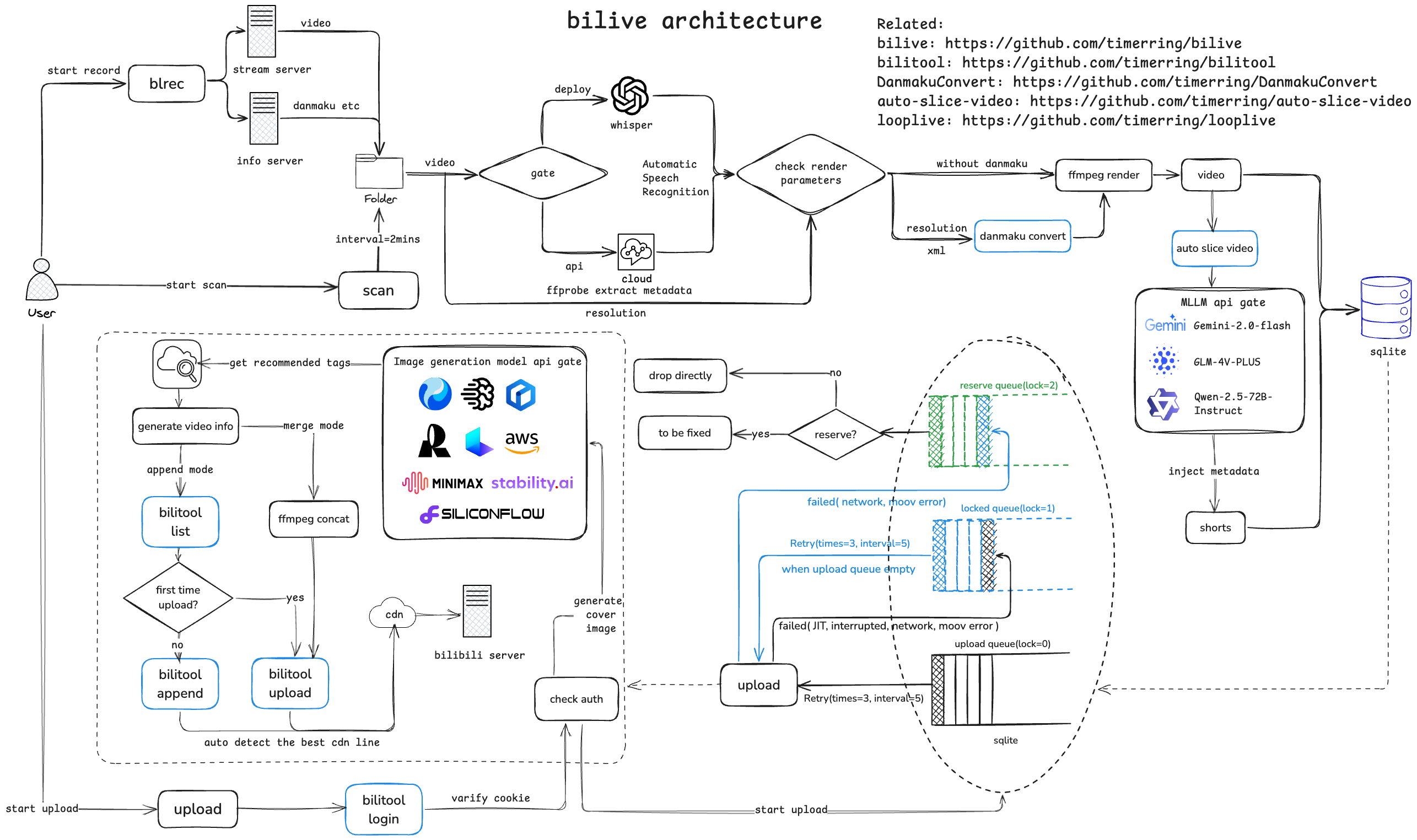
|
||||

|
||||
|
||||
## 3. 测试硬件
|
||||
|
||||
@@ -168,8 +170,9 @@ pip install -r requirements.txt
|
||||
> [!TIP]
|
||||
> - 有关自动切片的配置在 `bilive.toml` 文件的 `[slice]` 部分。
|
||||
> - `auto_slice` 默认为 false, 即不进行自动切片。
|
||||
> - 可以通过单元测试调试你自己的 prompt,单元测试在 `tests/test_autoslice.py`,执行 `python -m unittest` 即可,后接 `tests.test_autoslice` 测试整个模块,`tests.test_autoslice.TestXXXMain` 测试某个模型。
|
||||
|
||||
MLLM 模型主要用于自动切片后的切片标题生成,此功能默认关闭,如果需要打开请将 `auto_slice` 参数设置为 `true`,并且写下你自己的 prompt,其他配置分别有:
|
||||
MLLM 模型主要用于自动切片后的切片标题生成,此功能默认关闭,如果需要打开请将 `auto_slice` 参数设置为 `true`,并且写下你自己的 `slice_prompt`(请包含关键词 `{artist}`会自动替换),其他配置分别有:
|
||||
- `slice_duration` 以秒为单位设置切片时长(不建议超过 180 秒)。
|
||||
- `slice_num` 设置切片数量。
|
||||
- `slice_overlap` 设置切片重叠时长。切片采用滑动窗口法处理,细节内容请见 [auto-slice-video](https://github.com/timerring/auto-slice-video)
|
||||
@@ -178,11 +181,11 @@ MLLM 模型主要用于自动切片后的切片标题生成,此功能默认关
|
||||
|
||||
接下来配置模型有关的 `mllm_model` 参数即对应的 api-key,请自行根据链接注册账号并且申请对应 api key,填写在对应的参数中,请注意以下模型只有你在 `mllm_model` 参数中设置的那个模型会生效。
|
||||
|
||||
| Company | Alicloud | zhipu | Google |
|
||||
|----------------|-----------------------|------------------|-------------------|
|
||||
| Name | Qwen-2.5-72B-Instruct | GLM-4V-PLUS | Gemini-2.0-flash |
|
||||
| `mllm_model` | `qwen` | `zhipu` | `gemini` |
|
||||
| `API key` | [qwen_api_key](https://bailian.console.aliyun.com/?apiKey=1) | [zhipu_api_key](https://www.bigmodel.cn/invite?icode=shBtZUfNE6FfdMH1R6NybGczbXFgPRGIalpycrEwJ28%3D) | [gemini_api_key](https://aistudio.google.com/app/apikey) |
|
||||
| Company | Alicloud | zhipu | Google | SenseNova |
|
||||
|----------------|-----------------------|------------------|-------------------|-------------------|
|
||||
| Name | Qwen-2.5-72B-Instruct | GLM-4V-PLUS | Gemini-2.0-flash | SenseNova V6 Pro |
|
||||
| `mllm_model` | `qwen` | `zhipu` | `gemini` | `sensenova` |
|
||||
| `API key` | [qwen_api_key](https://bailian.console.aliyun.com/?apiKey=1) | [zhipu_api_key](https://www.bigmodel.cn/invite?icode=shBtZUfNE6FfdMH1R6NybGczbXFgPRGIalpycrEwJ28%3D) | [gemini_api_key](https://aistudio.google.com/app/apikey) | [sensenova_api_key](https://console.sensecore.cn/aistudio/management/api-key) |
|
||||
|
||||
|
||||
#### 2.3 Image Generation Model(自动生成视频封面)
|
||||
|
||||
1
assets/sensenova-brand-color.svg
Normal file
1
assets/sensenova-brand-color.svg
Normal file
{kind=link}
File diff suppressed because one or more lines are too long
|
After Width: | Height: | Size: 6.8 KiB |
@@ -17,23 +17,24 @@ inference_model = "small" # If you choose "deploy", you should download the infe
|
||||
# You can change the title as you like, eg.
|
||||
title = "{date}直播" # Key words: {artist}, {date}, {title}, {source_link}
|
||||
description = "录制请征求主播同意,若未经同意就录制,所引起的任何法律问题均由该违规录制的 b 站账号承担。" # Key words: {artist}, {date}, {title}, {source_link}
|
||||
tid = # The tid of the video, see https://bilitool.timerring.com/tid.html
|
||||
tid = # The tid of the video(int), see https://bilitool.timerring.com/tid.html
|
||||
gift_price_filter = 1 # The gift whose price is less than this value will be filtered, unit: RMB
|
||||
reserve_for_fixing = false # If encounter MOOV crash error, delete the video or reserve for fixing
|
||||
upload_line = "auto" # The upload line to be used, default None is auto detect(recommended), if you want to specify, it can be "bldsa", "ws", "tx", "qn", "bda2".
|
||||
|
||||
[slice]
|
||||
auto_slice = false # General control: true or false
|
||||
slice_prompt = "" # Write your own slice prompt here, key word: {artist}
|
||||
slice_duration = 60 # better not exceed 300 seconds
|
||||
slice_num = 2 # the number of slices
|
||||
slice_overlap = 30 # the overlap of slices(seconds) see my package https://github.com/timerring/auto-slice-video for more details
|
||||
slice_step = 1 # the step of slices(seconds)
|
||||
min_video_size = 200 # The minimum video size to be sliced (MB)
|
||||
mllm_model = "qwen" # the multi-model LLMs, can be "qwen" or "gemini" or "zhipu"
|
||||
slice_prompt = "" # Write your own slice prompt here
|
||||
qwen_api_key = "" # Apply for your own Qwen API key at https://bailian.console.aliyun.com/?apiKey=1
|
||||
zhipu_api_key = "" # Apply for your own GLM-4v-Plus API key at https://www.bigmodel.cn/invite?icode=shBtZUfNE6FfdMH1R6NybGczbXFgPRGIalpycrEwJ28%3D
|
||||
gemini_api_key = "" # Apply for your own Gemini API key at https://aistudio.google.com/app/apikey
|
||||
sensenova_api_key = "" # Apply for your own SenseNova API key at https://console.sensecore.cn/aistudio/management/api-key
|
||||
|
||||
[cover]
|
||||
generate_cover = false # whether to generate cover
|
||||
|
||||
@@ -15,14 +15,14 @@ def gemini_generate_title(video_path, artist):
|
||||
model="models/gemini-2.0-flash",
|
||||
contents=types.Content(
|
||||
parts=[
|
||||
types.Part(text=SLICE_PROMPT),
|
||||
types.Part(text=SLICE_PROMPT.format(artist=artist)),
|
||||
types.Part(
|
||||
inline_data=types.Blob(data=video_bytes, mime_type="video/mp4")
|
||||
),
|
||||
]
|
||||
),
|
||||
)
|
||||
scan_log.info("使用 Gemini-2.0-flash 生成切片标题")
|
||||
scan_log.info(f"Prompt: {SLICE_PROMPT}")
|
||||
scan_log.info(f"生成的切片标题为: {response.text}")
|
||||
scan_log.info("Using Gemini-2.0-flash to generate slice title")
|
||||
scan_log.info(f"Prompt: {SLICE_PROMPT.format(artist=artist)}")
|
||||
scan_log.info(f"Generated slice title: {response.text}")
|
||||
return response.text
|
||||
|
||||
@@ -23,7 +23,7 @@ def gemini_generate_title(video_path, artist):
|
||||
raise ValueError(video_file.state.name)
|
||||
|
||||
# Create the prompt.
|
||||
prompt = SLICE_PROMPT
|
||||
prompt = SLICE_PROMPT.format(artist=artist)
|
||||
|
||||
# Set the model to Gemini Flash.
|
||||
model = genai.GenerativeModel(model_name="models/gemini-2.0-flash")
|
||||
@@ -33,7 +33,7 @@ def gemini_generate_title(video_path, artist):
|
||||
)
|
||||
# delete the video file
|
||||
genai.delete_file(video_file.name)
|
||||
scan_log.info("使用 Gemini-2.0-flash 生成切片标题")
|
||||
scan_log.info(f"Prompt: {SLICE_PROMPT}")
|
||||
scan_log.info(f"生成的切片标题为: {response.text}")
|
||||
scan_log.info("Using Gemini-2.0-flash to generate slice title")
|
||||
scan_log.info(f"Prompt: {SLICE_PROMPT.format(artist=artist)}")
|
||||
scan_log.info(f"Generated slice title: {response.text}")
|
||||
return response.text
|
||||
|
||||
@@ -31,12 +31,12 @@ def qwen_generate_title(video_path, artist):
|
||||
"type": "video_url",
|
||||
"video_url": {"url": f"data:video/mp4;base64,{base64_video}"},
|
||||
},
|
||||
{"type": "text", "text": SLICE_PROMPT},
|
||||
{"type": "text", "text": SLICE_PROMPT.format(artist=artist)},
|
||||
],
|
||||
},
|
||||
],
|
||||
)
|
||||
scan_log.info("使用 Qwen-2.5-72B-Instruct 生成切片标题")
|
||||
scan_log.info(f"Prompt: {SLICE_PROMPT}")
|
||||
scan_log.info(f"生成的切片标题为: {completion.choices[0].message.content}")
|
||||
scan_log.info("Using Qwen-2.5-72B-Instruct to generate slice title")
|
||||
scan_log.info(f"Prompt: {SLICE_PROMPT.format(artist=artist)}")
|
||||
scan_log.info(f"Generated slice title: {completion.choices[0].message.content}")
|
||||
return completion.choices[0].message.content.strip('"')
|
||||
|
||||
115
src/autoslice/mllm_sdk/sensenova_sdk.py
Normal file
115
src/autoslice/mllm_sdk/sensenova_sdk.py
Normal file
@@ -0,0 +1,115 @@
|
||||
import requests
|
||||
import os
|
||||
from src.config import SENSENOVA_API_KEY, SLICE_PROMPT
|
||||
from src.log.logger import scan_log
|
||||
|
||||
|
||||
class SenseNova:
|
||||
def __init__(self, model_id):
|
||||
self.model_id = model_id
|
||||
self.headers = {"Authorization": "Bearer " + SENSENOVA_API_KEY}
|
||||
|
||||
# file size limit: 45 MB
|
||||
def _upload_video(self, file_path):
|
||||
"""Upload the video to the SenseNova server and return the file_id
|
||||
Docs: https://console.sensecore.cn/micro/help/docs/model-as-a-service/nova/overview/file/CreateFile/
|
||||
|
||||
Args:
|
||||
file_path (str): The path to the video file
|
||||
Returns:
|
||||
str: The file_id of the uploaded video / None if failed
|
||||
"""
|
||||
data = {"description": "string", "scheme": "MULTIMODAL_2"}
|
||||
url = "https://file.sensenova.cn/v1/files"
|
||||
try:
|
||||
with open(file_path, "rb") as file:
|
||||
files = {"file": file}
|
||||
r = requests.post(url, headers=self.headers, data=data, files=files)
|
||||
if r.status_code == 200:
|
||||
file_id = r.json()["id"]
|
||||
scan_log.info(f"upload video success, file_id: {file_id}")
|
||||
return file_id
|
||||
else:
|
||||
scan_log.error(f"upload video failed, {r.text}")
|
||||
return None
|
||||
except Exception as e:
|
||||
scan_log.error(e)
|
||||
|
||||
def _delete_video(self, file_id):
|
||||
"""Delete the video from the SenseNova server
|
||||
Docs: https://console.sensecore.cn/micro/help/docs/model-as-a-service/nova/overview/file/DeleteFile
|
||||
|
||||
Args:
|
||||
file_id (str): The file_id of the video to delete
|
||||
"""
|
||||
url = "https://file.sensenova.cn/v1/files/" + file_id
|
||||
r = requests.delete(url, headers=self.headers)
|
||||
if r.status_code == 200:
|
||||
scan_log.info("delete video success")
|
||||
else:
|
||||
scan_log.error("delete video failed")
|
||||
|
||||
def chat_multi(self, query, file_id):
|
||||
"""Chat with the SenseNova
|
||||
Docs: https://console.sensecore.cn/micro/help/docs/model-as-a-service/nova/vision/ChatCompletions/
|
||||
|
||||
Args:
|
||||
query (str): The query to chat with the SenseNova server
|
||||
file_id (str): The file_id of the video to chat with
|
||||
"""
|
||||
url = "https://api.sensenova.cn/v1/llm/chat-completions"
|
||||
if file_id is None:
|
||||
scan_log.error("upload video failed")
|
||||
return None
|
||||
payload = {
|
||||
"model": self.model_id,
|
||||
"messages": [
|
||||
{
|
||||
"content": [
|
||||
{"type": "video_file_id", "video_file_id": file_id},
|
||||
{"text": query, "type": "text"},
|
||||
],
|
||||
"role": "user",
|
||||
}
|
||||
],
|
||||
"max_new_tokens": 1024,
|
||||
"repetition_penalty": 1.05,
|
||||
"temperature": 0.7,
|
||||
"stream": False,
|
||||
"top_p": 0.25,
|
||||
}
|
||||
r = requests.post(url, json=payload, headers=self.headers)
|
||||
# request_id = r.headers["x-request-id"]
|
||||
# first_trunk = r.elapsed.total_seconds()
|
||||
# print("first_trunk: ", first_trunk)
|
||||
# print(r, request_id, r.headers, r.text)
|
||||
if r.status_code == 200:
|
||||
title_with_french_quotes = r.json()["data"]["choices"][0]["message"]
|
||||
title = title_with_french_quotes.replace("《", "").replace("》", "")
|
||||
return title
|
||||
else:
|
||||
scan_log.error(f"chat multi failed, {r.text}")
|
||||
return None
|
||||
|
||||
|
||||
def sensenova_generate_title(file_path, artist, model_id="SenseNova-V6-Pro"):
|
||||
query = SLICE_PROMPT.format(artist=artist)
|
||||
scan_log.info(f"Using {model_id} to generate slice title")
|
||||
scan_log.info(f"Prompt: {query}")
|
||||
try:
|
||||
sense_nova = SenseNova(model_id)
|
||||
file_id = sense_nova._upload_video(file_path)
|
||||
if file_id is None:
|
||||
scan_log.error("upload video failed")
|
||||
return None
|
||||
title = sense_nova.chat_multi(query, file_id)
|
||||
if title:
|
||||
sense_nova._delete_video(file_id)
|
||||
scan_log.info(f"Generated slice title: {title}")
|
||||
return title
|
||||
else:
|
||||
scan_log.error("Generate slice title failed")
|
||||
return None
|
||||
except Exception as e:
|
||||
scan_log.error(e)
|
||||
return None
|
||||
@@ -18,12 +18,12 @@ def zhipu_glm_4v_plus_generate_title(video_path, artist):
|
||||
"role": "user",
|
||||
"content": [
|
||||
{"type": "video_url", "video_url": {"url": video_base}},
|
||||
{"type": "text", "text": SLICE_PROMPT},
|
||||
{"type": "text", "text": SLICE_PROMPT.format(artist=artist)},
|
||||
],
|
||||
}
|
||||
],
|
||||
)
|
||||
scan_log.info("使用 Zhipu-glm-4v-plus 生成切片标题")
|
||||
scan_log.info(f"Prompt: {SLICE_PROMPT}")
|
||||
scan_log.info(f"生成的切片标题为: {response.choices[0].message.content}")
|
||||
scan_log.info("Using Zhipu-glm-4v-plus to generate slice title")
|
||||
scan_log.info(f"Prompt: {SLICE_PROMPT.format(artist=artist)}")
|
||||
scan_log.info(f"Generated slice title: {response.choices[0].message.content}")
|
||||
return response.choices[0].message.content.replace("《", "").replace("》", "")
|
||||
|
||||
@@ -25,6 +25,10 @@ def title_generator(model_type):
|
||||
from .mllm_sdk.qwen_sdk import qwen_generate_title
|
||||
|
||||
return qwen_generate_title(video_path, artist)
|
||||
elif model_type == "sensenova":
|
||||
from .mllm_sdk.sensenova_sdk import sensenova_generate_title
|
||||
|
||||
return sensenova_generate_title(video_path, artist)
|
||||
else:
|
||||
scan_log.error(f"Unsupported model type: {model_type}")
|
||||
return None
|
||||
|
||||
@@ -76,6 +76,7 @@ MLLM_MODEL = config.get("slice", {}).get("mllm_model")
|
||||
ZHIPU_API_KEY = config.get("slice", {}).get("zhipu_api_key")
|
||||
GEMINI_API_KEY = config.get("slice", {}).get("gemini_api_key")
|
||||
QWEN_API_KEY = config.get("slice", {}).get("qwen_api_key")
|
||||
SENSENOVA_API_KEY = config.get("slice", {}).get("sensenova_api_key")
|
||||
|
||||
GENERATE_COVER = config.get("cover", {}).get("generate_cover")
|
||||
IMAGE_GEN_MODEL = config.get("cover", {}).get("image_gen_model")
|
||||
|
||||
0
tests/__init__.py
Normal file
0
tests/__init__.py
Normal file
40
tests/test_autoslice.py
Normal file
40
tests/test_autoslice.py
Normal file
@@ -0,0 +1,40 @@
|
||||
import unittest
|
||||
from src.autoslice.mllm_sdk.sensenova_sdk import sensenova_generate_title
|
||||
from src.autoslice.mllm_sdk.qwen_sdk import qwen_generate_title
|
||||
|
||||
# from src.autoslice.mllm_sdk.gemini_new_sdk import gemini_generate_title
|
||||
from src.autoslice.mllm_sdk.gemini_old_sdk import gemini_generate_title
|
||||
from src.autoslice.mllm_sdk.zhipu_sdk import zhipu_glm_4v_plus_generate_title
|
||||
|
||||
|
||||
class BaseTest(unittest.TestCase):
|
||||
file_path = "your_video_path"
|
||||
artist = "your_artist"
|
||||
|
||||
|
||||
class TestGeminiMain(BaseTest):
|
||||
def test_gemini_generate_title(self):
|
||||
title = gemini_generate_title(self.file_path, self.artist)
|
||||
self.assertIsNotNone(title)
|
||||
|
||||
|
||||
class TestQwenMain(BaseTest):
|
||||
def test_qwen_generate_title(self):
|
||||
title = qwen_generate_title(self.file_path, self.artist)
|
||||
self.assertIsNotNone(title)
|
||||
|
||||
|
||||
class TestSenseNovaMain(BaseTest):
|
||||
def test_sensenova_generate_title(self):
|
||||
title = sensenova_generate_title(self.file_path, self.artist)
|
||||
self.assertIsNotNone(title)
|
||||
|
||||
|
||||
class TestZhipuMain(BaseTest):
|
||||
def test_zhipu_generate_title(self):
|
||||
title = zhipu_glm_4v_plus_generate_title(self.file_path, self.artist)
|
||||
self.assertIsNotNone(title)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
unittest.main()
|
||||
Reference in New Issue
Block a user